Fast and Large-Scale Unbalanced Optimal Transport via its Semi-Dual and Adaptive Gradient Methods
COLT 2026 · 2026
F. Genans
📄 Paper In Unbalanced Optimal Transport (UOT), we investigate the entropically regularized semi-dual objective. We prove the convergence rates of SGD and ASGD in both stochastic and semi-discrete settings. For the discrete case, we introduce a smoothness-adaptive Nesterov accelerated gradient descent scheme. We establish its global convergence rate and demonstrate an enhanced local convergence of O(log(1/δ)/√ε) to achieve δ-accuracy.
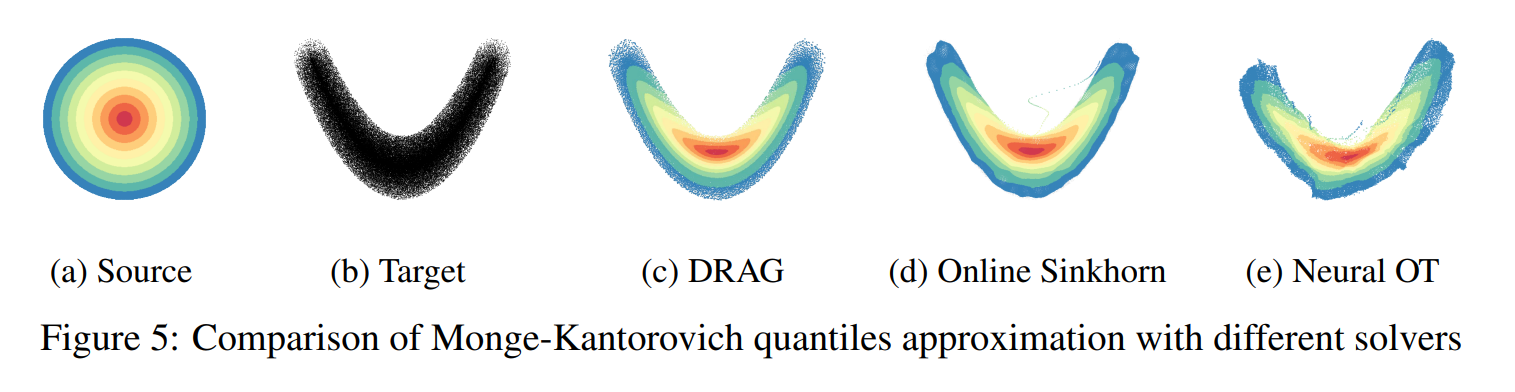
Decreasing Entropic Regularization Averaged Gradient for Semi-Discrete Optimal Transport
NeurIPS 2025 · 2025
F. Genans, A. Godichon-Baggioni, F.-X. Vialard, O. Wintenberger
📄 Paper We introduce DRAG, a stochastic algorithm for semi-discrete Optimal Transport that decreases entropic regularization during training. This yields unbiased estimates and faster convergence than fixed-regularization methods, with both theory and experiments confirming its efficiency.
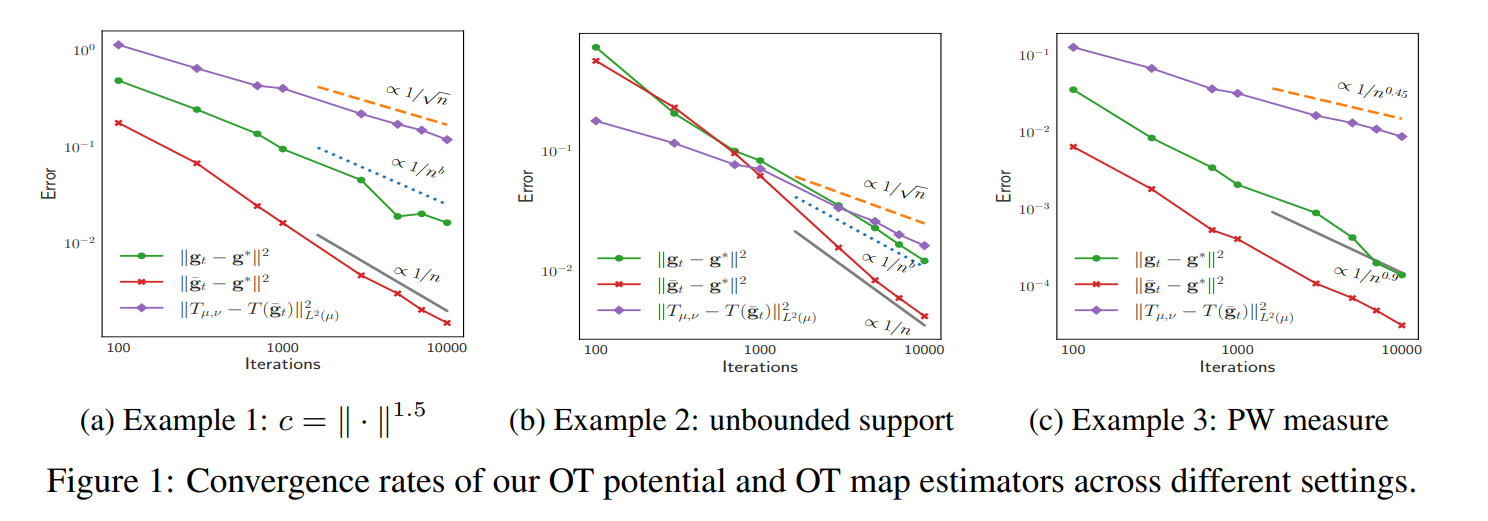
Stochastic Optimization in Semi-Discrete Optimal Transport: Convergence Analysis and Minimax Rate
NeurIPS 2025 — Spotlight · 2025
F. Genans, A. Godichon-Baggioni, F.-X. Vialard, O. Wintenberger
📄 Paper We prove that Stochastic Gradient Descent can efficiently approximate the OT map in the semi-discrete setting, even in an online fashion, establishing the first minimax convergence guarantees for a broad class of cost functions and non-compact measures in this setting.